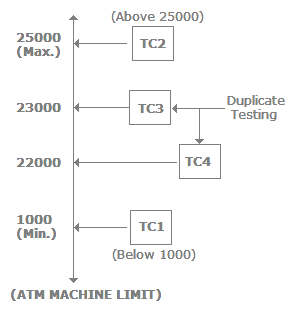
- Can you explain boundary value analysis?In some projects there are scenarios where we need to do boundary value testing. For instance, let's say for a bank application you can withdraw a maximum of 25000 and a minimum of 100. So in boundary value testing we only test the exact boundaries rather than hitting in the middle. That means we only test above the max and below the max. This covers all scenarios. The following figure shows the boundary value testing for the bank application which we just described. TC1 and TC2 are sufficient to test all conditions for the bank. TC3 and TC4 are just duplicate/redundant test cases which really do not add any value to the testing. So by applying proper boundary value fundamentals we can avoid duplicate test cases, which do not add value to the testing.
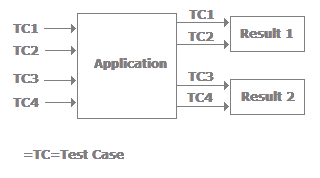
- Can you explain equivalence partitioning?In equivalence partitioning we identify inputs which are treated by the system in the same way and produce the same results. You can see from the following figure applications TC1 and TC2 give the same results (i.e., TC3 and TC4 both give the same result, Result2). In short, we have two redundant test cases. By applying equivalence partitioning we minimize the redundant test cases.
 So apply the test below to see if it forms an equivalence class or not:
So apply the test below to see if it forms an equivalence class or not:- All the test cases should test the same thing.
- They should produce the same results.
- If one test case catches a bug, then the other should also catch it.
- If one of them does not catch the defect, then the other should not catch it.
- Can you explain random/monkey testing?Random testing is sometimes called monkey testing. In Random testing, data is generated randomly often using a tool. For instance, the following figure shows how randomly-generated data is sent to the system. This data is generated either using a tool or some automated mechanism. With this randomly generated input the system is then tested and results are observed accordingly.
 Random testing has the following weakness:
Random testing has the following weakness:- They are not realistic.
- Many of the tests are redundant and unrealistic.
- You will spend more time analyzing results.
- You cannot recreate the test if you do not record what data was used for testing.
Sunday, October 28, 2018
Testing Techniques
Saturday, October 27, 2018
Six Sigma
- What is Six Sigma?Six Sigma is a statistical measure of variation in a process. We say a process has achieved Six Sigma if the quality is 3.4 DPMO (Defect per Million Opportunities). It's a problem-solving methodology that can be applied to a process to eliminate the root cause of defects and costs associated with it.

- Can you explain the different methodology for the execution and the design process stages in Six Sigma?The main focus of Six Sigma is to reduce defects and variations in the processes. DMAIC and DMADV are the models used in most Six Sigma initiatives.
 DMADV is the model for designing processes while DMAIC is used for improving the process.The DMADV model includes the following five steps:
DMADV is the model for designing processes while DMAIC is used for improving the process.The DMADV model includes the following five steps:- Define: Determine the project goals and the requirements of customers (external and internal).
- Measure: Assess customer needs and specifications.
- Analyze: Examine process options to meet customer requirements.
- Design: Develop the process to meet the customer requirements.
- Verify: Check the design to ensure that it's meeting customer requirements
 The DMAIC model includes the following five steps:
The DMAIC model includes the following five steps:- Define the projects, goals, and deliverables to customers (internal and external). Describe and quantify both the defects and the expected improvements.
- Measure the current performance of the process. Validate data to make sure it is credible and set the baselines.
- Analyze and determine the root cause(s) of the defects. Narrow the causal factors to the vital few.
- Improve the process to eliminate defects. Optimize the vital few and their interrelationships.
- Control the performance of the process. Lock down the gains.
- Can you explain the fish bone/Ishikawa diagram?There are situations where we need to analyze what caused the failure or problem in a project. The fish bone or Ishikawa diagram is one important concept which can help you find the root cause of the problem. Fish bone was conceptualized by Ishikawa, so in honor of its inventor, this concept was named the Ishikawa diagram. Inputs to conduct a fish bone diagram come from discussion and brainstorming with people involved in the project. The following figure shows the structure of the Ishikawa diagram.
 The main bone is the problem which we need to address to know what caused the failure. For instance, the following fish bone is constructed to find what caused the project failure. To know this cause we have taken four main bones as inputs: Finance, Process, People, and Tools.
The main bone is the problem which we need to address to know what caused the failure. For instance, the following fish bone is constructed to find what caused the project failure. To know this cause we have taken four main bones as inputs: Finance, Process, People, and Tools.
Sunday, October 21, 2018
Capability Maturity Model Integration
- What is CMMI and what's the advantage of implementing it in an organization?CMMI stands for Capability Maturity Model Integration. It is a process improvement approach that provides companies with the essential elements of an effective process. CMMI can serve as a good guide for process improvement across a project, organization, or division.CMMI was formed by using multiple previous CMM processes.The following are the areas which CMMI addresses:
 Systems engineering: This covers development of total systems. System engineers concentrate on converting customer needs to product solutions and supports them throughout the product lifecycle.Software engineering: Software engineers concentrate on the application of systematic, disciplined, and quantifiable approaches to the development, operation, and maintenance of software.Integrated Product and Process Development (IPPD): Integrated Product and Process Development (IPPD) is a systematic approach that achieves a timely collaboration of relevant stakeholders throughout the life of the product to better satisfy customer needs, expectations, and requirements. This section mostly concentrates on the integration part of the project for different processes. For instance, it's possible that your project is using services of some other third party component. In such situations the integration is a big task itself, and if approached in a systematic manner, can be handled with ease.Software acquisition: Many times an organization has to acquire products from other organizations. Acquisition is itself a big step for any organization and if not handled in a proper manner means a disaster is sure to happen.
Systems engineering: This covers development of total systems. System engineers concentrate on converting customer needs to product solutions and supports them throughout the product lifecycle.Software engineering: Software engineers concentrate on the application of systematic, disciplined, and quantifiable approaches to the development, operation, and maintenance of software.Integrated Product and Process Development (IPPD): Integrated Product and Process Development (IPPD) is a systematic approach that achieves a timely collaboration of relevant stakeholders throughout the life of the product to better satisfy customer needs, expectations, and requirements. This section mostly concentrates on the integration part of the project for different processes. For instance, it's possible that your project is using services of some other third party component. In such situations the integration is a big task itself, and if approached in a systematic manner, can be handled with ease.Software acquisition: Many times an organization has to acquire products from other organizations. Acquisition is itself a big step for any organization and if not handled in a proper manner means a disaster is sure to happen. - What's the difference between implementation and institutionalization?Both of these concepts are important while implementing a process in any organization. Any new process implemented has to go through these two phases.
 Implementation: It is just performing a task within a process area. A task is performed according to a process but actions performed to complete the process are not ingrained in the organization. That means the process involved is done according to the individual point of view. When an organization starts to implement any process it first starts at this phase, i.e., implementation, and then when this process looks good it is raised to the organization level so that it can be implemented across organizations.Institutionalization: Institutionalization is the output of implementing the process again and again. The difference between implementation and institutionalization is in implementation if the person who implemented the process leaves the company the process is not followed, but if the process is institutionalized then even if the person leaves the organization, the process is still followed.
Implementation: It is just performing a task within a process area. A task is performed according to a process but actions performed to complete the process are not ingrained in the organization. That means the process involved is done according to the individual point of view. When an organization starts to implement any process it first starts at this phase, i.e., implementation, and then when this process looks good it is raised to the organization level so that it can be implemented across organizations.Institutionalization: Institutionalization is the output of implementing the process again and again. The difference between implementation and institutionalization is in implementation if the person who implemented the process leaves the company the process is not followed, but if the process is institutionalized then even if the person leaves the organization, the process is still followed. - Can you explain the different maturity levels in a staged representation?There are five maturity levels in a staged representation as shown in the following figure.Maturity Level 1 (Initial): In this level everything is adhoc. Development is completely chaotic with budget and schedules often exceeded. In this scenario we can never predict quality.Maturity Level 2 (Managed): In the managed level basic project management is in place. But the basic project management and practices are followed only in the project level.Maturity Level 3 (Defined): To reach this level the organization should have already achieved level 2. In the previous level the good practices and process were only done at the project level. But in this level all these good practices and processes are brought to the organization level. There are set and standard practices defined at the organization level which every project should follow. Maturity Level 3 moves ahead with defining a strong, meaningful, organizational approach to developing products. An important distinction between Maturity Levels 2 and 3 is that at Level 3, processes are described in more detail and more rigorously than at Level 2 and are at an organization level.Maturity Level 4 (Quantitatively measured): To start with, this level of organization should have already achieved Level 2 and Level 3. In this level, more statistics come into the picture. Organization controls the project by statistical and other quantitative techniques. Product quality, process performance, and service quality are understood in statistical terms and are managed throughout the life of the processes. Maturity Level 4 concentrates on using metrics to make decisions and to truly measure whether progress is happening and the product is becoming better. The main difference between Levels 3 and 4 are that at Level 3, processes are qualitatively predictable. At Level 4, processes are quantitatively predictable. Level 4 addresses causes of process variation and takes corrective action.Maturity Level 5 (Optimized): The organization has achieved goals of maturity levels 2, 3, and 4. In this level, processes are continually improved based on an understanding of common causes of variation within the processes. This is like the final level; everyone on the team is a productive member, defects are minimized, and products are delivered on time and within the budget boundary.The following figure shows, in detail, all the maturity levels in a pictorial fashion.

Saturday, October 20, 2018
Software Testing Basics
- Can you explain the PDCA cycle and where testing fits in?Software testing is an important part of the software development process. In normal software development there are four important steps, also referred to, in short, as the PDCA (Plan, Do, Check, Act) cycle.
 Let's review the four steps in detail.
Let's review the four steps in detail.- Plan: Define the goal and the plan for achieving that goal.
- Do/Execute: Depending on the plan strategy decided during the plan stage we do execution accordingly in this phase.
- Check: Check/Test to ensure that we are moving according to plan and are getting the desired results.
- Act: During the check cycle, if any issues are there, then we take appropriate action accordingly and revise our plan again.
So developers and other stakeholders of the project do the "planning and building," while testers do the check part of the cycle. Therefore, software testing is done in check part of the PDCA cyle. - What is the difference between white box, black box, and gray box testing?Black box testing is a testing strategy based solely on requirements and specifications. Black box testing requires no knowledge of internal paths, structures, or implementation of the software being tested.White box testing is a testing strategy based on internal paths, code structures, and implementation of the software being tested. White box testing generally requires detailed programming skills.There is one more type of testing called gray box testing. In this we look into the "box" being tested just long enough to understand how it has been implemented. Then we close up the box and use our knowledge to choose more effective black box tests.
 The above figure shows how both types of testers view an accounting application during testing. Black box testers view the basic accounting application. While during white box testing the tester knows the internal structure of the application. In most scenarios white box testing is done by developers as they know the internals of the application. In black box testing we check the overall functionality of the application while in white box testing we do code reviews, view the architecture, remove bad code practices, and do component level testing.
The above figure shows how both types of testers view an accounting application during testing. Black box testers view the basic accounting application. While during white box testing the tester knows the internal structure of the application. In most scenarios white box testing is done by developers as they know the internals of the application. In black box testing we check the overall functionality of the application while in white box testing we do code reviews, view the architecture, remove bad code practices, and do component level testing. - Can you explain usability testing?Usability testing is a testing methodology where the end customer is asked to use the software to see if the product is easy to use, to see the customer's perception and task time. The best way to finalize the customer point of view for usability is by using prototype or mock-up software during the initial stages. By giving the customer the prototype before the development start-up we confirm that we are not missing anything from the user point of view.

- What are the categories of defects?There are three main categories of defects:

- Wrong: The requirements have been implemented incorrectly. This defect is a variance from the given specification.
- Missing: There was a requirement given by the customer and it was not done. This is a variance from the specifications, an indication that a specification was not implemented, or a requirement of the customer was not noted properly.
- Extra: A requirement incorporated into the product that was not given by the end customer. This is always a variance from the specification, but may be an attribute desired by the user of the product. However, it is considered a defect because it's a variance from the existing requirements.
Sunday, October 14, 2018
Operating Systems
- Explain the concept of Reentrancy?It is a useful, memory-saving technique for multiprogrammed timesharing systems. A Reentrant Procedure is one in which multiple users can share a single copy of a program during the same period. Reentrancy has 2 key aspects: The program code cannot modify itself, and the local data for each user process must be stored separately. Thus, the permanent part is the code, and the temporary part is the pointer back to the calling program and local variables used by that program. Each execution instance is called activation. It executes the code in the permanent part, but has its own copy of local variables/parameters. The temporary part associated with each activation is the activation record. Generally, the activation record is kept on the stack.Note: A reentrant procedure can be interrupted and called by an interrupting program, and still execute correctly on returning to the procedure.
- Explain Belady's Anomaly?Also called FIFO anomaly. Usually, on increasing the number of frames allocated to a process virtual memory, the process execution is faster, because fewer page faults occur. Sometimes, the reverse happens, i.e., the execution time increases even when more frames are allocated to the process. This is Belady's Anomaly. This is true for certain page reference patterns.
- What is a binary semaphore? What is its use?A binary semaphore is one, which takes only 0 and 1 as values. They are used to implement mutual exclusion and synchronize concurrent processes.
- What is thrashing?It is a phenomenon in virtual memory schemes when the processor spends most of its time swapping pages, rather than executing instructions. This is due to an inordinate number of page faults.
Friday, October 12, 2018
Interview Questions and Answers
- What is a FIFO?FIFO are otherwise called as 'named pipes'. FIFO (first-in-first-out) is a special file which is said to be data transient. Once data is read from named pipe, it cannot be read again. Also, data can be read only in the order written. It is used in interprocess communication where a process writes to one end of the pipe (producer) and the other reads from the other end (consumer).
- How do you create special files like named pipes and device files?The system call mknod creates special files in the following sequence.
- kernel assigns new inode,
- sets the file type to indicate that the file is a pipe, directory or special file,
- If it is a device file, it makes the other entries like major, minor device numbers.
If the device is a disk, major device number refers to the disk controller and minor device number is the disk. - Discuss the mount and unmount system calls.The privileged mount system call is used to attach a file system to a directory of another file system; the unmount system call detaches a file system. When you mount another file system on to your directory, you are essentially splicing one directory tree onto a branch in another directory tree. The first argument to mount call is the mount point, that is , a directory in the current file naming system. The second argument is the file system to mount to that point. When you insert a cdrom to your unix system's drive, the file system in the cdrom automatically mounts to "/dev/cdrom" in your system.
- How does the inode map to data block of a file?Inode has 13 block addresses. The first 10 are direct block addresses of the first 10 data blocks in the file. The 11th address points to a one-level index block. The 12th address points to a two-level (double in-direction) index block. The 13th address points to a three-level(triple in-direction)index block. This provides a very large maximum file size with efficient access to large files, but also small files are accessed directly in one disk read.
- What is a shell?A shell is an interactive user interface to an operating system services that allows an user to enter commands as character strings or through a graphical user interface. The shell converts them to system calls to the OS or forks off a process to execute the command. System call results and other information from the OS are presented to the user through an interactive interface. Commonly used shells are sh,csh,ks etc.
Saturday, October 6, 2018
Interview Questions and Answers
- Which TCP/IP port does SQL Server run on? How can it be changed?SQL Server runs on port 1433. It can be changed from the Network Utility TCP/IP properties.
- What are the difference between clustered and a non-clustered index?
- A clustered index is a special type of index that reorders the way records in the table are physically stored. Therefore table can have only one clustered index. The leaf nodes of a clustered index contain the data pages.
- A non clustered index is a special type of index in which the logical order of the index does not match the physical stored order of the rows on disk. The leaf node of a non clustered index does not consist of the data pages. Instead, the leaf nodes contain index rows.
- What are the different index configurations a table can have?A table can have one of the following index configurations:
- No indexes
- A clustered index
- A clustered index and many nonclustered indexes
- A nonclustered index
- Many nonclustered indexes
- What are different types of Collation Sensitivity?
- Case sensitivity - A and a, B and b, etc.
- Accent sensitivity
- Kana Sensitivity - When Japanese kana characters Hiragana and Katakana are treated differently, it is called Kana sensitive.
Friday, October 5, 2018
SQL Server 2008
- What are the basic functions for master, msdb, model, tempdb and resource databases?
- The master database holds information for all databases located on the SQL Server instance and is theglue that holds the engine together. Because SQL Server cannot start without a functioning masterdatabase, you must administer this database with care.
- The msdb database stores information regarding database backups, SQL Agent information, DTS packages, SQL Server jobs, and some replication information such as for log shipping.
- The tempdb holds temporary objects such as global and local temporary tables and stored procedures.
- The model is essentially a template database used in the creation of any new user database created in the instance.
- The resoure Database is a read-only database that contains all the system objects that are included with SQL Server. SQL Server system objects, such as sys.objects, are physically persisted in the Resource database, but they logically appear in the sys schema of every database. The Resource database does not contain user data or user metadata.
- What is Service Broker?Service Broker is a message-queuing technology in SQL Server that allows developers to integrate SQL Server fully into distributed applications. Service Broker is feature which provides facility to SQL Server to send an asynchronous, transactional message. it allows a database to send a message to another database without waiting for the response, so the application will continue to function if the remote database is temporarily unavailable.
- Where SQL server user names and passwords are stored in SQL server?They get stored in System Catalog Views sys.server_principals and sys.sql_logins.
- What is Policy Management?Policy Management in SQL SERVER 2008 allows you to define and enforce policies for configuring and managing SQL Server across the enterprise. Policy-Based Management is configured in SQL Server Management Studio (SSMS). Navigate to the Object Explorer and expand the Management node and the Policy Management node; you will see the Policies, Conditions, and Facets nodes.
Subscribe to:
Comments (Atom)